Simulating Users with State Alignment Beats Response Imitation
We build user simulators that accurately reflect real users by generating natural-language latent states aligned with ground-truth responses.
 Read the paper
Read the paper
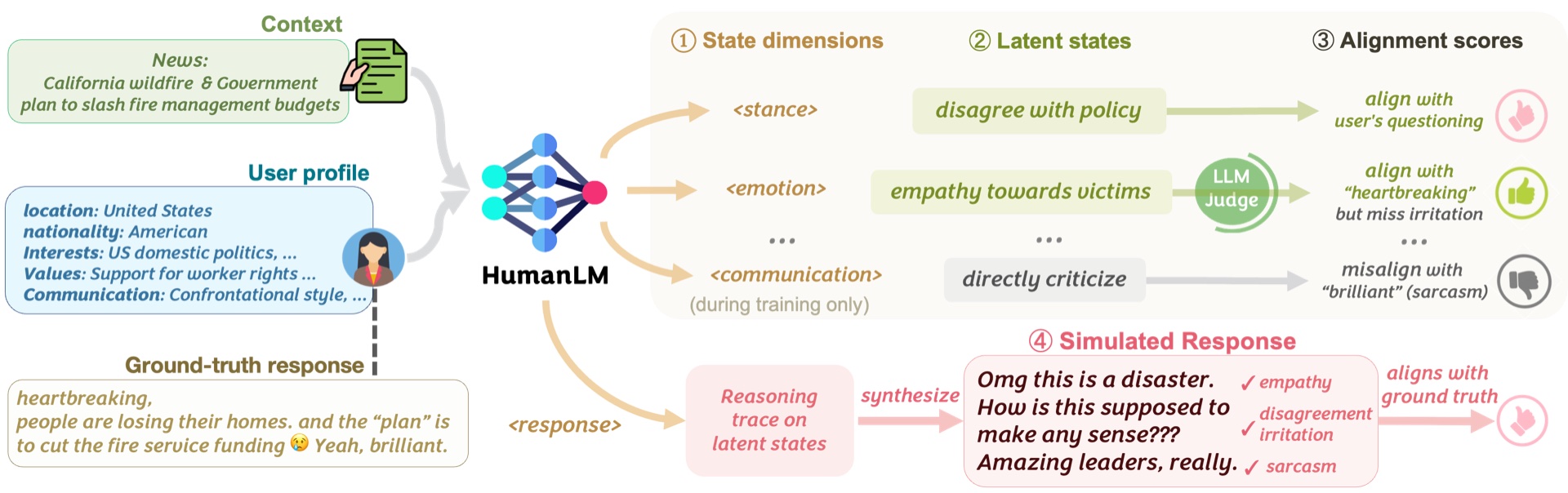
Large Language Models are increasingly used to simulate how specific users respond to any context, enabling more user-centric applications. However, existing user simulators mostly imitate surface-level patterns and language styles, which fails to reflect the underlying state of real users. To address these limitations, we propose HumanLM, a novel training framework which builds user simulators that accurately reflect real users. Our key insight is that we generate natural-language latent states that align with the ground truth responses through reinforcement learning.
@article{wu2026humanlm,
title={HUMANLM: Simulating Users with State Alignment Beats Response Imitation},
url={https://humanlm.stanford.edu/},
author={Wu, Shirley and Choi, Evelyn and Khatua, Arpandeep and
Wang, Zhanghan and He-Yueya, Joy and Weerasooriya, Tharindu Cyril and
Wei, Wei and Yang, Diyi and Leskovec, Jure and Zou, James},
year={2026}
}