Think of a persona as everything you know about a person: where they're from, what they care about, how they talk, what they believe in. When we build systems that simulate how real users behave, we use these personas as a kind of identity card. Swap the persona, and you get a different simulated user.
The more you know about someone, the better you can predict what they'd say. Therefore, we'd like our user simulators to have as much persona information as possible.
But in the real world, that information is often incomplete. People restrict personal information for privacy reasons, new users arrive on a platform with barely any history, and profile fields get left blank. So what actually happens to a user simulator when it only has a partial picture of who it is supposed to be?
Background
In the HUMANUAL benchmark, each user persona has five structured fields: Demographics, Interests, Values, Communication, and Statistics. During training, we give the model a user's persona and some context, and ask it to generate a response that reflects that user's likely stance, emotion, or beliefs, not just mimic surface-level patterns.
We evaluate models using a response alignment score, where Claude Haiku judges how well the model's outputs match what the real user actually said, across these latent dimensions. Our main approach is HumanLM, compared against a GRPO baseline. We test on HUMANUAL-Opinion, a dataset of responses to 1,000 Reddit threads about personal moral dilemmas, like family conflicts and life choices.
What happens when persona information is missing?
To find out, we gave models only one persona field at inference time, out of five total. As you might expect, performance drops. The simulator is working with one fifth of the information it was trained on.
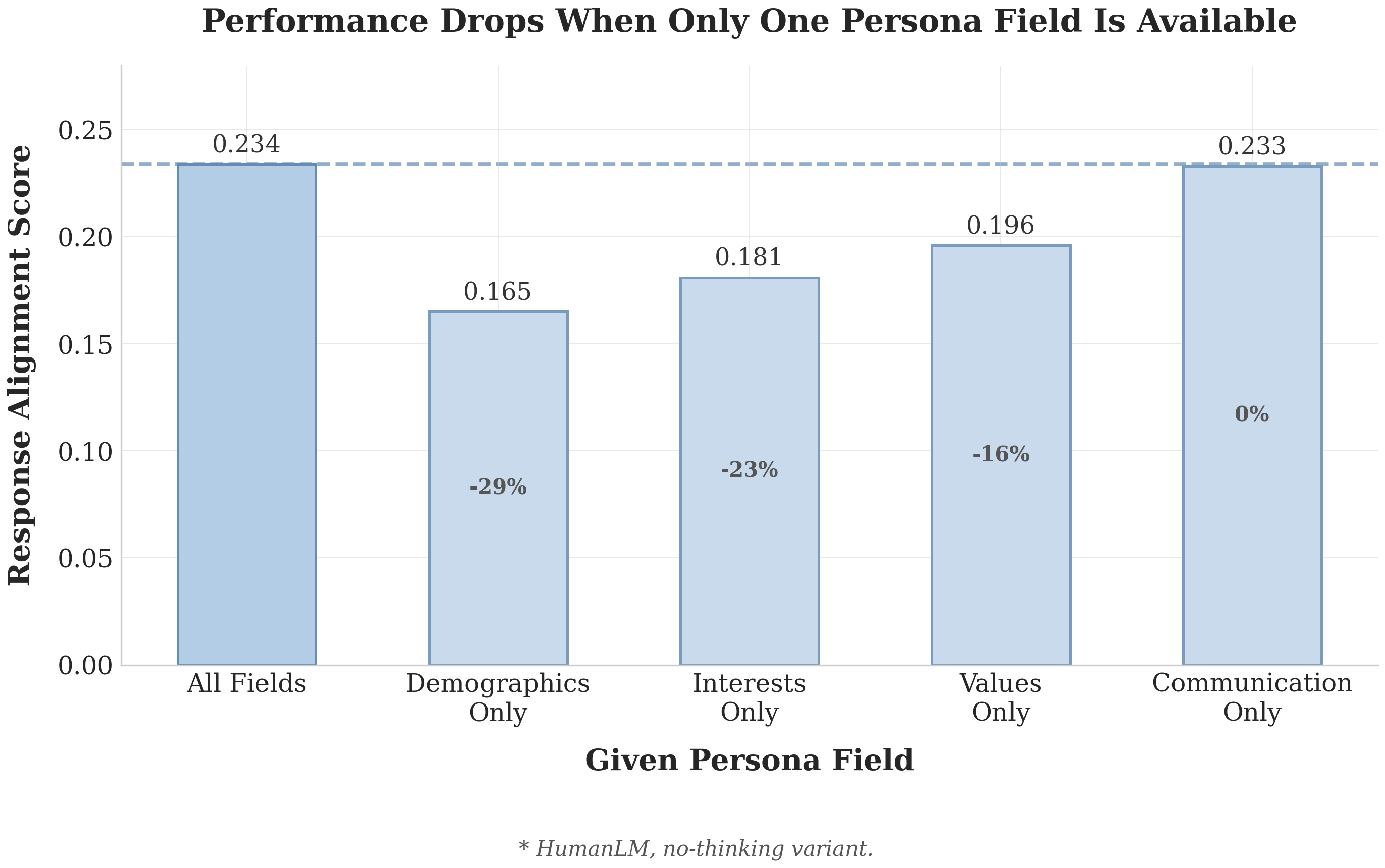
So, how do we make sure that when a user has limited information, we can still simulate them to the best extent we can?
The fix is quite simple: during training, we randomly hide some of the persona information from the model. Each of the five persona fields has a 60% chance of being removed for any given training example. We call this field dropout. The idea is to force the model to learn how to work with less, so that during test time it knows how to handle incomplete personas.
Better alignment on HUMANUAL-Opinion
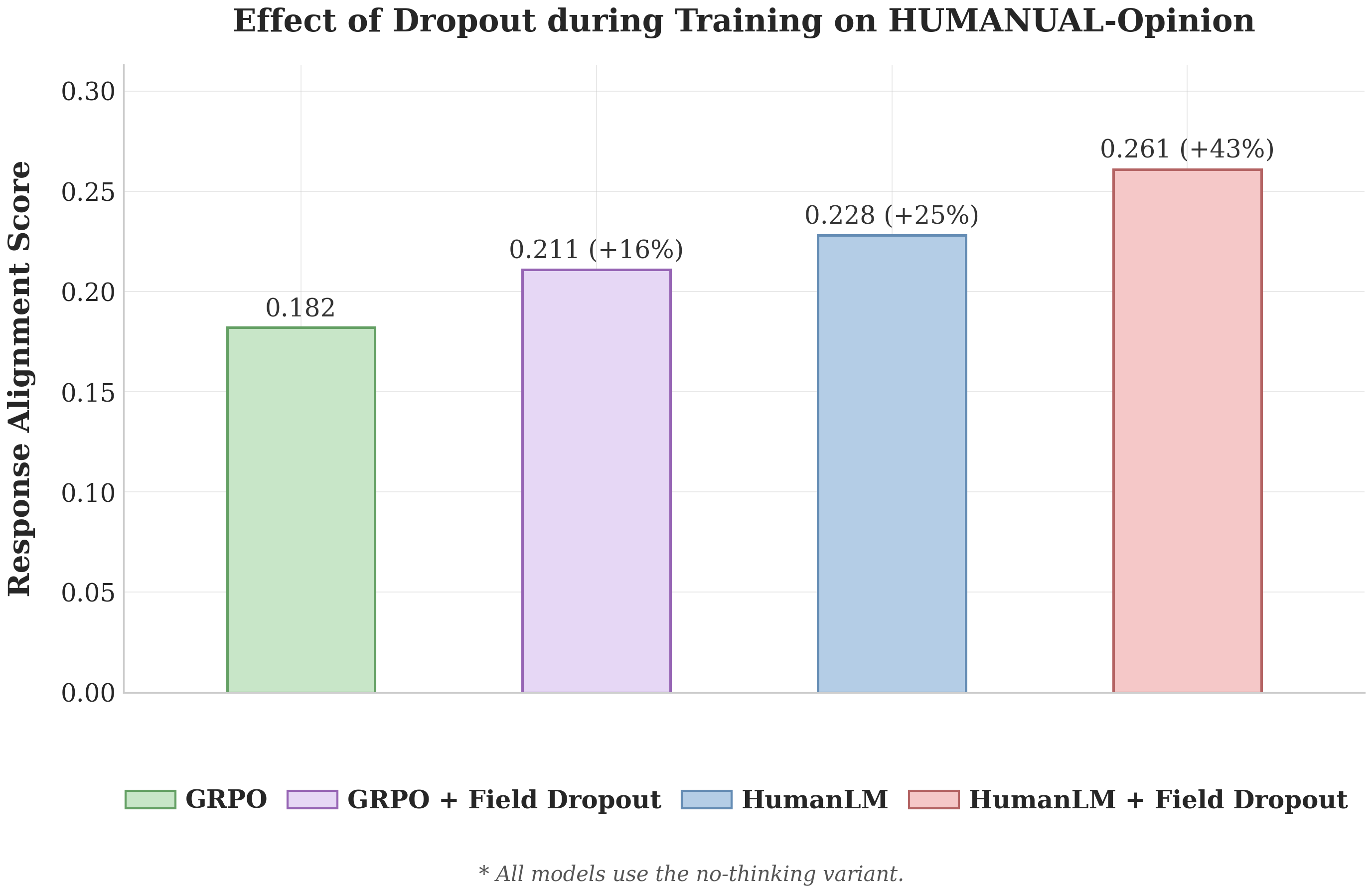
This suggests field dropout is a broadly useful technique, regardless of the underlying training method.
Robust when only one persona field is available
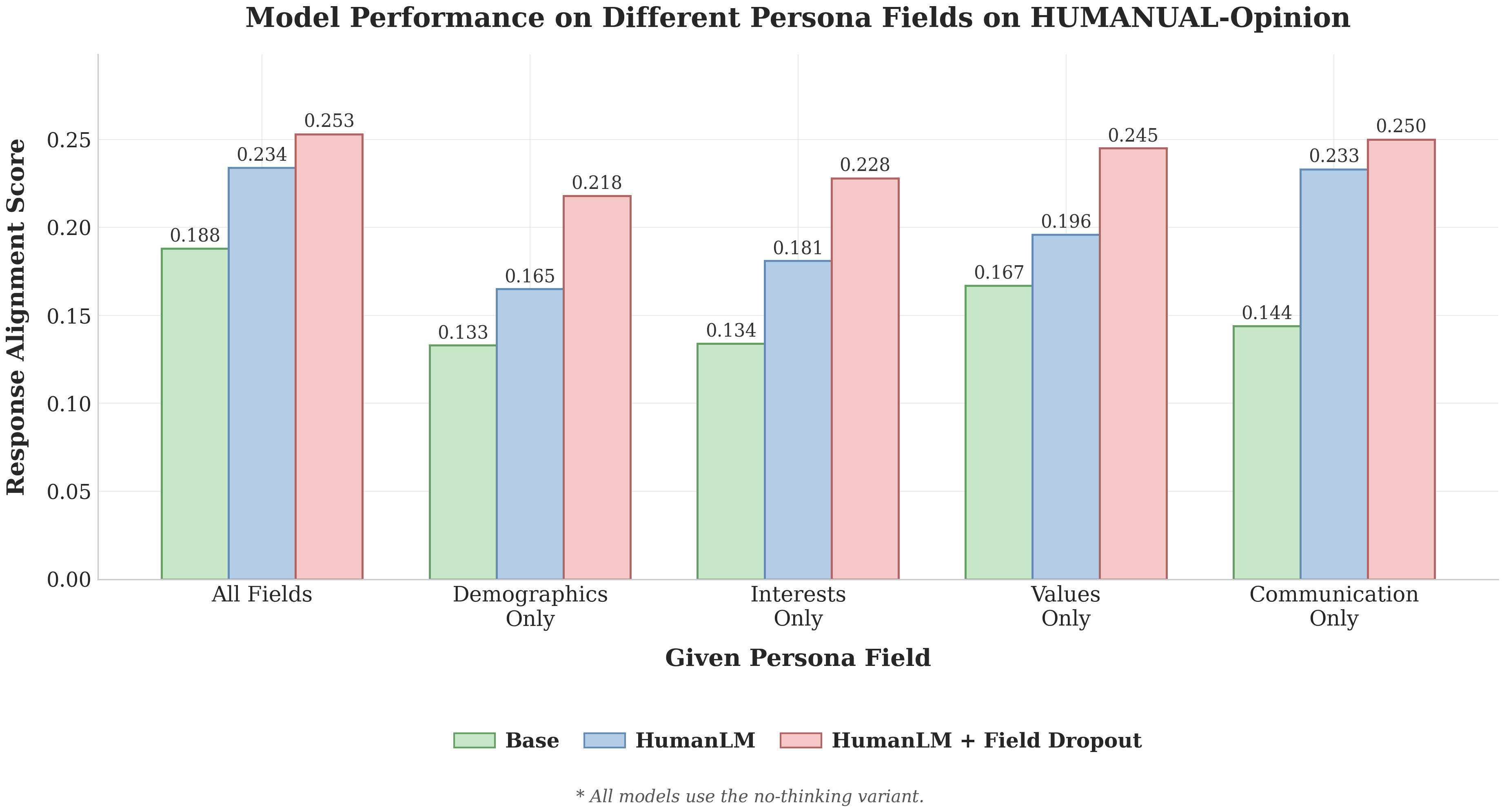
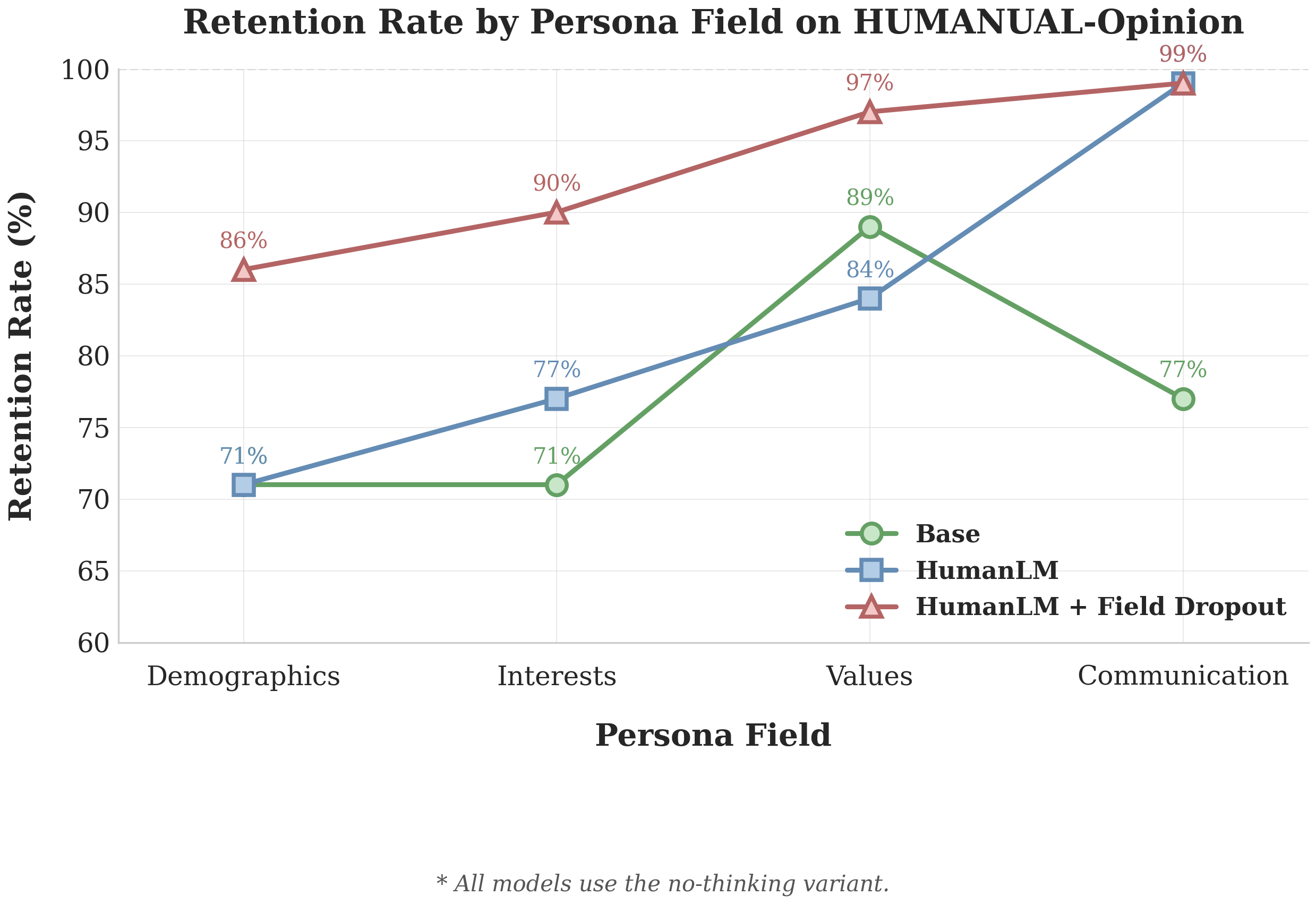
Going back to the single-field setting: HumanLM trained with field dropout maintains 86–90% of its full-information performance across all single-field conditions. Averaged across the four fields, field dropout gives HumanLM a 23% boost over the version without it.
One interesting finding: the Communication field alone nearly matches full-persona performance for both HumanLM variants. This makes sense since in HumanLM, the Communication field doesn't just shape internal user states, but also how these states get translated into a final response. For the base model, the Values field was most useful, which aligns with the nature of HUMANUAL-Opinion: to predict someone's take on a moral dilemma, knowing their values is most helpful.
Transfer Robustness: Generalizing to Item Dropout
Field dropout removes whole persona categories. But real-world missing data is often messier. Maybe a user filled in their interests, but only listed two things instead of ten. Or their demographics section is half empty.
To test generalization, we introduced item dropout at test time: each individual line within a field is randomly dropped with probability p. Crucially, no model was trained with item dropout. We just wanted to see if the robustness would carry over.
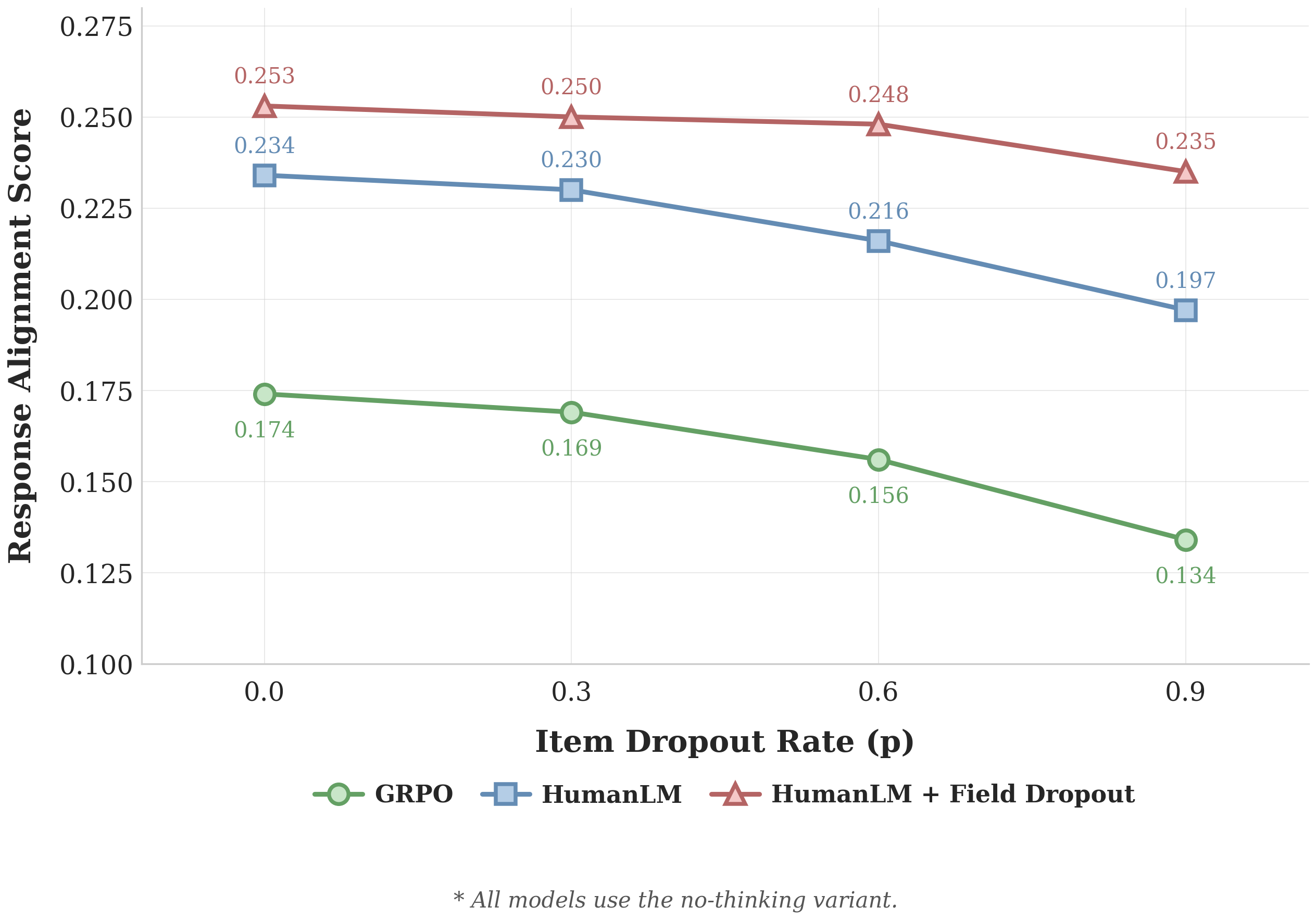
It does! At p=0.9, where 90% of within-field content is removed, HumanLM with field dropout still retains 92% of its original score. HumanLM without field dropout retains 84%, and GRPO drops to 77%. The more data is withheld, the wider the gap gets. Field dropout seems to build a skill for handling general incompleteness, not just the specific kind it was trained on.
Takeaway
Field dropout requires no architectural changes or additional data. Yet our results show that training with this simple intervention yields user simulators that are not only more accurate, but also more robust to real-world, incomplete profiles.