Today, many people use synthetic data to train models, with good reasons. Synthetic data is cheap, controllable, and scalable. Like many people, we started with synthetic data to train our user simulators. And, spoiler alert if you haven't read our paper, we eventually decided to collect real user data to train our models. This effort of trying out synthetic data surprisingly took about a month of our time.
The gap between synthetic and real responses
To give you a sense of how different synthetic and real user data really are, consider a Reddit post asking whether social media and politics are ruining your life.
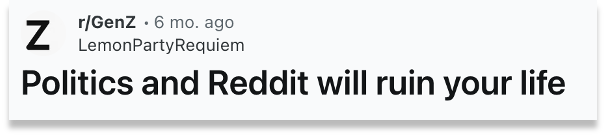
If you just ask a model to comment on this post (Figure 2), its answer is rather neutral: "if you use it consciously, it's fine. But if you… it can ruin your peace of mind." You can tell the model knows two directions to go, agree or disagree. Like a helpful assistant, it blends them into one balanced response.
If you further engineer a better prompt with instructions on how to behave like a human, the model knows to be more decisive and picks a side.
This seems promising. Until you realize that across many generations to the same prompt, the model agrees or disagrees for very similar reasons. But this is beyond mere "intra-model repetition," where a single model consistently generates similar responses, a problem noted by Jian et al. (2025). The real problem is what you find when you look at the actual human responses.
In reality, beyond just agreeing or disagreeing, many people mock the poster:
Others express entirely different emotional registers:
Or provide structural analysis of why Reddit is becoming political:

And even among those who simply agree or disagree, real comments offer far more interesting perspectives than anything synthetic data tends to produce. Consider these two examples you would hardly ever sample from a language model:


When the reward goes up but nothing improves
Even with this observation, we didn't give up on synthetic data right away. One can argue that even if a gap exists, the model can still learn something useful from it. Then we saw this:
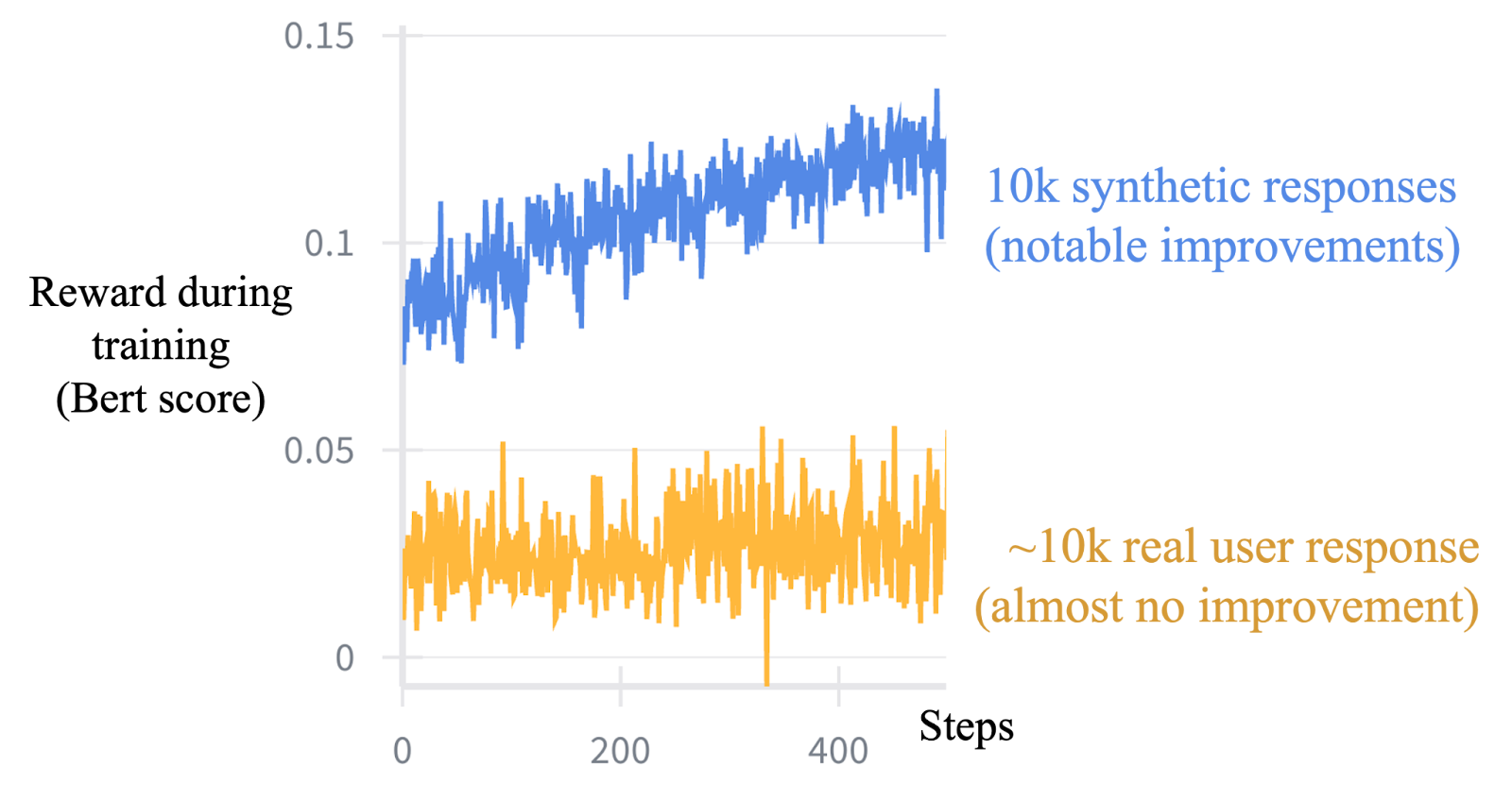
For context: we use BERTScore as a reward here, it computes embedding similarity between ground truth responses and generated ones. We train two models, one on 10k synthetic responses and one on ~10k real user responses, using the same algorithm (standard GRPO), the same amount of data, and the same training pipeline and compute.
The results diverge sharply. We see clear improvements on synthetic data, but no meaningful improvement on real data. An algorithm designer looking only at synthetic results could easily declare success. But that same algorithm fails to move the needle on real data, neither during training nor, likely, at test time when the model needs to generalize.
Why this happens: the Platonic convergence problem
To understand the root cause, we took Qwen3-8B, an open-source LLM with no exposure to either dataset, and measured how "surprised" it is by each type of response. We computed the mean token-level log probability of real and synthetic responses on Reddit, using Qwen3-8B's own outputs and GPT-4o-mini's synthetic outputs as reference points.
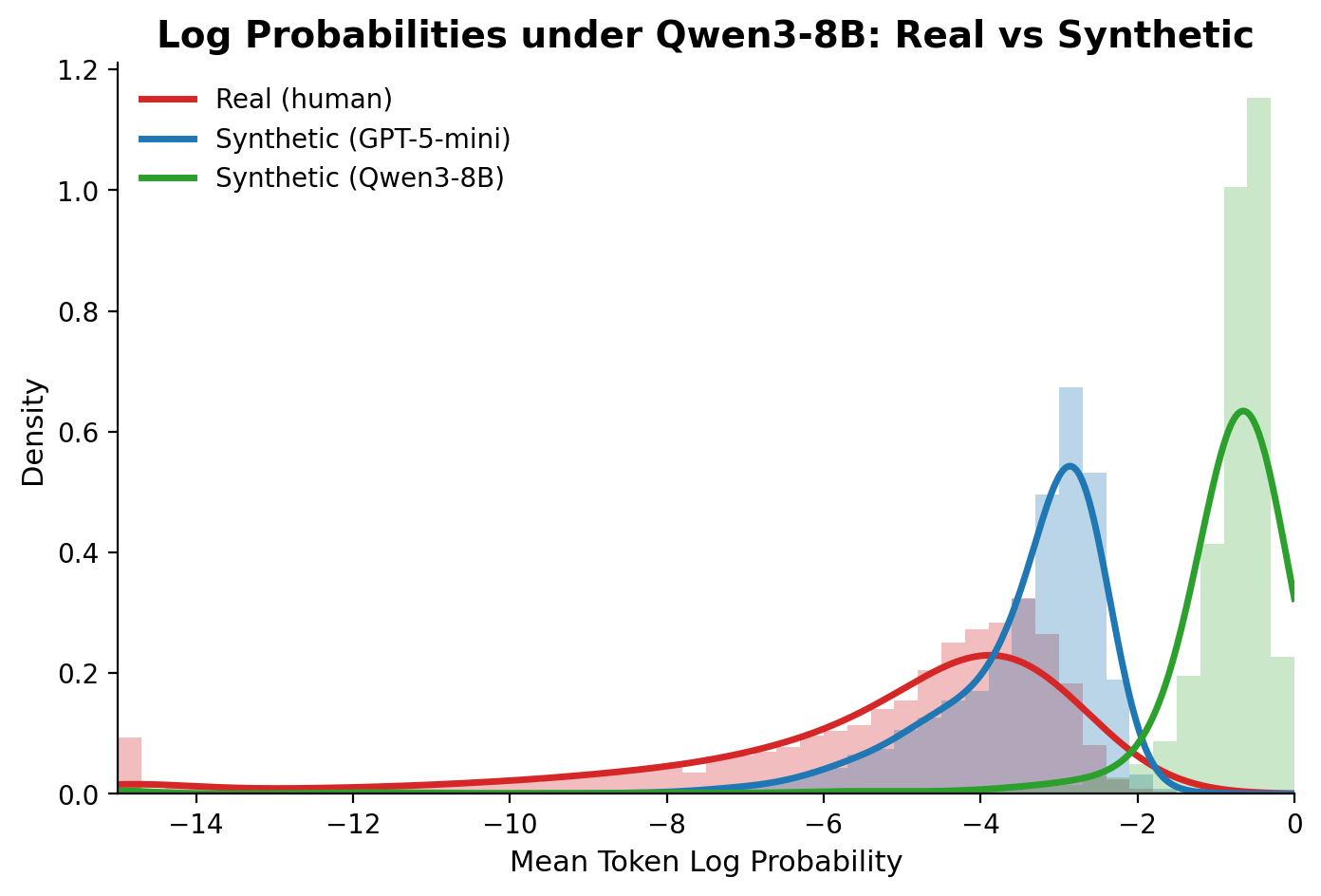
What's striking is that GPT-4o-mini's outputs are also quite predictable to Qwen3-8B, even though they come from a completely different model. This is consistent with the Platonic Representation Hypothesis (Huh et al., 2024), which argues that neural networks are converging toward a shared statistical model of reality. Different LLMs, despite different architectures and training data, end up with similar representations, so synthetic text from any LLM lands in roughly the same narrow, high-likelihood region.
Real human responses, by contrast, spread across a much wider range, into regions these converging representations would basically never produce on their own.
This is the core problem. When we train on synthetic data and see the reward go up, we're not teaching the model to simulate humans. We're teaching it to stay within the shared representational space that all LLMs already occupy. The reward signal from real data pushes the model outside of it, which is harder to optimize, but that's where the actual humans are.
Takeaway
In our case, this is a sobering result for synthetic data: the improvements you observe on synthetic benchmarks may simply not transfer to the real users you actually want to simulate. For this study, we decided to go real all the way, starting from the data.
That said, the "in our case" qualifier matters. Synthetic data might still be a useful reference if you engineer a diverse enough set of system prompts to improve variety and coverage. A promising direction might be using a small amount of real user data as a seed to generate more targeted synthetic data. But for now, when it comes to simulating the full breadth of how real people actually respond, there's no substitute for the real thing.